How to Create Two Identical Symmetric Keys
SQL Server offers a sophisticated encryption key management system allowing for multiple levels of symmetric and asymmetric keys that protect each other. (See: The SQL Server Encryption Hierarchy) However, there is one use case that is only marginally supported by SQL Server: Creating the same symmetric key in two databases or even on two separate servers.
There are only two methods to achieve this. The first is the use of an External Key Management solution in the form of an EKM module. However, EKM modules are often rather pricey investments and therefore not for everyone. The second method, and the only one not requiring external components, is a special form of the CREATE SYMMETRIC KEY statement. It allows us to specify a key source and an identity value. If identical values are used for these parameters, the resulting keys will be identical too.
CREATE SYMMETRIC KEY WITH KEYSOURCE Example
The extended syntax of the CREATE SYMMETRIC KEY statement is fairly straight forward, you just need to add the KEY_SOURCE and IDENTITY_VALUE clauses right after specifying the algorithm:
WITH ALGORITHM = AES_256,
KEY_SOURCE = '********************',
IDENTITY_VALUE = 'SymmetricKey1'
ENCRYPTION BY CERTIFICATE KeyProtection;
[/sql]
The key source is used to generate the actual key bits. It is using some form of key expansion algorithm. However, and that is my biggest concern with this method, which algorithm is used is not published. That means, while we can select the AES 256 algorithm for the key, if we actually get AES 256 level protection is unclear.
To clarify, the encryption algorithm used for an AES 256 key is always AES 256. However, if the key can be guessed easier than a random 256-bit key, you are dealing with a weakness. As we do not know how the key is derived, we also do not know how secure it is.
The Identity Value
The string that is specified in the IDENTITY_VALUE clause is not used for the generation of the actual key. It is only used to generate the key GUID that helps SQL Server identify the key necessary for decryption of an encrypted value. The DECRYPTBYKEY function does not allow us to specify the symmetric key to use for the decryption. Instead, SQL Server stores the GUID of the key that was used to encrypt the value as part of that value. That way, SQL Server will always know which key to use.
When looking at the documentation, you can get the impression, that the IDENTITY_VALUE needs to be kept a secret. However, it being unknown does not in any way increase security. If the KEY_SOURCE is known but the identity value isn't, we can just create a new key with a new GUID and then replace the key GUID within the encrypted value. As that value is just prepended to the actual cipher text, this is a simple string substitution operation.
To demonstrate that the IDENTITY_VALUE does not affect the key bits, let us look at this example:
GO
CREATE SYMMETRIC KEY SymmetricKey1 WITH ALGORITHM = AES_256, KEY_SOURCE = 'Secret1', IDENTITY_VALUE = 'SymmetricKey1' ENCRYPTION BY CERTIFICATE KeyProtection;
CREATE SYMMETRIC KEY SymmetricKey2 WITH ALGORITHM = AES_256, KEY_SOURCE = 'Secret1', IDENTITY_VALUE = 'SymmetricKey2' ENCRYPTION BY CERTIFICATE KeyProtection;
GO
SELECT SK.name,
DECRYPTBYCERT(C.certificate_id,KE.crypt_property) AS decrypted_key,
SK.key_guid
FROM sys.key_encryptions AS KE
JOIN sys.symmetric_keys AS SK
ON KE.key_id = SK.symmetric_key_id
JOIN sys.certificates AS C
ON KE.thumbprint = C.thumbprint
WHERE SK.name LIKE 'SymmetricKey_';
[/sql]
The script creates a certificate and two symmetric keys. The symmetric keys are created with different identity values but with the same secret. The script then uses the certificate to decrypt the actual key bits. As you can see in the following screenshot, the actual key bits are identical.
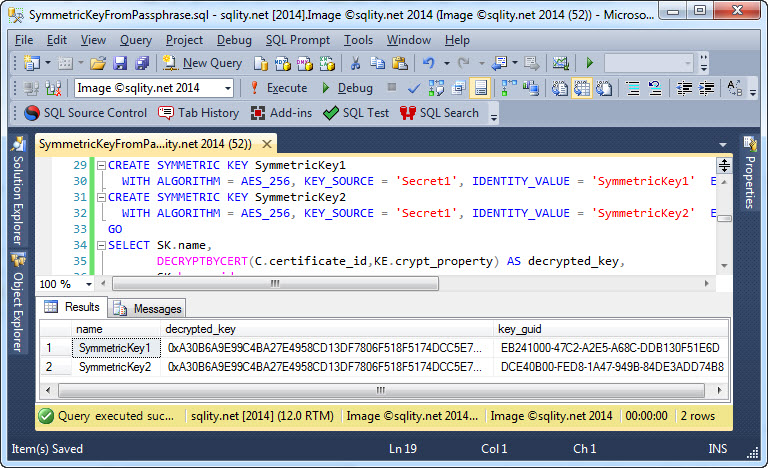
On the other hand, if you compare the above screenshot with the one below, you can also see that the value passed as KEY_SOURCE does not affect the generated key GUID:
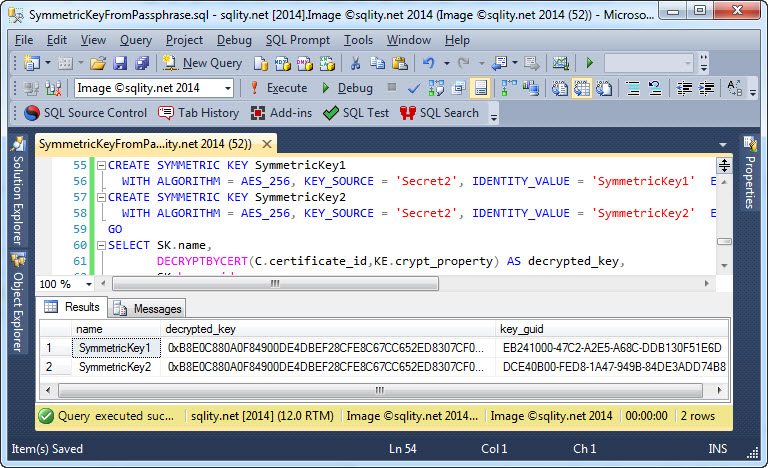
That means, that you do not need to keep the IDENTITY_VALUE a secret. However, the KEY_SOURCE has to be a secret, as anyone knowing it can easily re-generate the key and decrypt all your data.
Summary
The CREATE SYMMETRIC KEY statement allows us to specify a string as a KEY_SOURCE. That value is used to generate the actual key bits in a repeatable way. Therefore, we can use this feature to create the same key in different location.
Newsletter Sign Up
One Response to How to Create Two Identical Symmetric Keys
Leave a Reply
You must be logged in to post a comment.

We know to keep a database secure. We’ll help you to do the same.

From the sqlity.net blog
-
How to identify the SQL Server Service Account in T-SQL

-
How to Change a SQL Login’s Password

-
Hash Algorithms – How does SQL Server store Passwords?

-
How to Re-Create a Login with only a Hashed Password

-
B+Trees – How SQL Server Indexes are Stored on Disk

-
The Hidden SQL Server Gem: UPDATE from SELECT

-
A Join A Day – Nested Joins

-
Determine the Uptime of a SQL Server Instance

-
A Join A Day – The Left Anti Semi Join
-
Log Reuse Waits Explained: LOG_BACKUP

Pingback: Temporary Symmetric Key Conflicts - sqlity.net