The Deceiving Seek Operator [TSQL Tuesday #043 – Hello, Operator?]

T-SQL Tuesday #43 is hosted by Robert Farley (blog|g+|twitter).
This month's topic is "Hello, Operator?".
The Deceiving Seek Operator
Introduction
This T-SQL Tuesday is too great a topic to pass by. There are a lot of operators SQL Server uses to compile an execution plan that will return the data your query asked for. Some of them you keep running into regularly, like the Table-Scan Operator. Other ones are rarely seen, like the Assert Operator. (Both of them potentially point to a problem in your query.)
An Execution Plan Operator is actually a C++ object that implements three methods: Open, GetRow and Close. These objects get linked together in a tree structure to build the execution plan. Each operator gets rows from its direct child operator (or operators) by first calling the Open() method. Then the GetRow() method is called until no more rows are available or needed. Finally, the Close() method cleans up by for example releasing memory that was required by the child operator. This simple interface that is implemented by all operators allows SQL Server to place operators anywhere in any order in the execution plan. Because they all have the same interface, every operator can talk to every other operator as its child. That makes the whole system very flexible.
Today, rather than talking about how execution plans are constructed in general I am going to take a look at one operator that is often thought to be the Holy Grail in query optimization: The Seek Operator. If your query gets the data with a Scan Operator you are in a bad place, if it gets the data using a Seek Operator it is going to be blazing fast.
As most things in SQL Server this one is not actually that straight forward. For example, if the index seek has to be followed by a key lookup, things quickly look very different, at least if you are returning more than just a few rows. (Do a search on SQL Server Tipping Point for more info on this.)
What I am going to show you is that the Seek can actually be quite deceiving by executing a full Index Scan under the covers. But before we go there, let's do a quick refresher on Seeks and Scans
Seek and Scan Refresher
For this exercise I am going to create a large table first:
id INT IDENTITY(1,1),
key_fill CHAR(792) DEFAULT REPLICATE('key_fill',99),
d1 INT DEFAULT CHECKSUM(NEWID()),
page_fill CHAR(7200) DEFAULT REPLICATE('PageFill',900),
CONSTRAINT [PK:dbo.tst] PRIMARY KEY CLUSTERED (id, key_fill)
);
GO
MERGE dbo.tst t
USING(
SELECT TOP(100000)1 X
FROM sys.system_internals_partition_columns A,sys.system_internals_partition_columns B,sys.system_internals_partition_columns C,sys.system_internals_partition_columns D
)X
ON 1=0
WHEN NOT MATCHED THEN
INSERT DEFAULT VALUES;
[/sql]
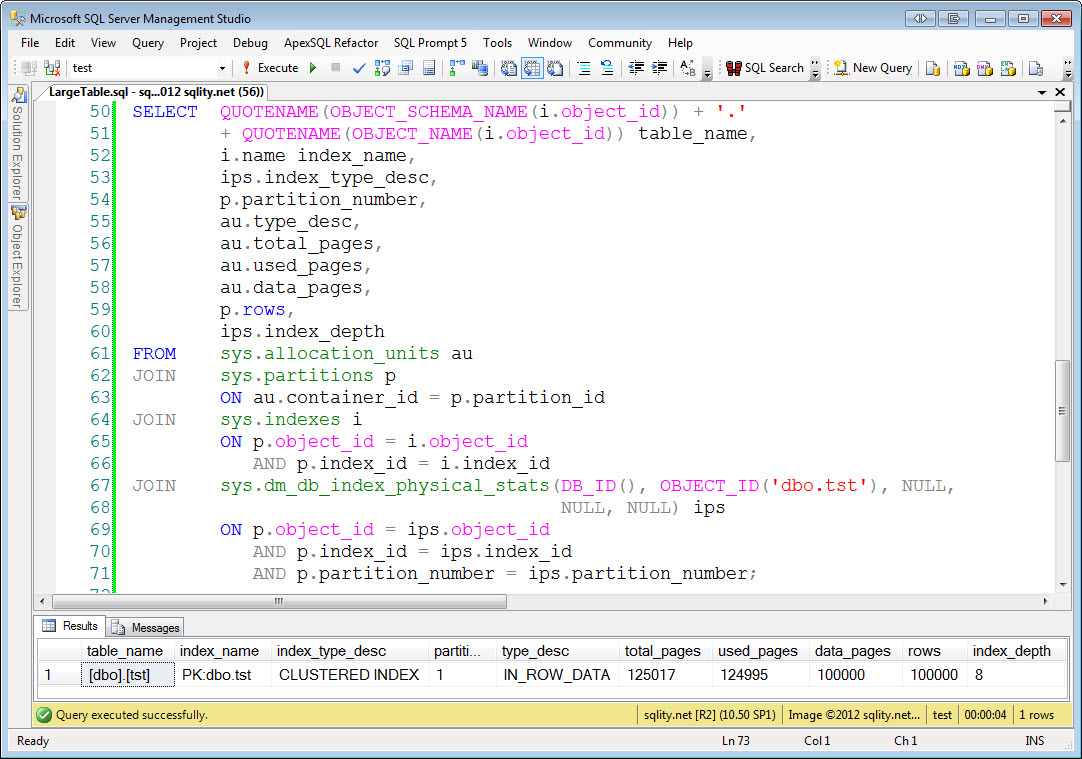
The code above creates an admittedly slightly crazy table dbo.tst and inserts 100,000 rows into it. The table is designed to use as many data pages as possible (actually one page per row) and as many supporting index pages as possible. If you execute this code you will end up with a table that is about one GB in size, has 100,000 data pages and about another 25,000 supporting clustered index pages making the clustered index B+Tree eight levels deep. You can run this query to confirm that:
+ QUOTENAME(OBJECT_NAME(i.object_id)) table_name,
i.name index_name,
ips.index_type_desc,
p.partition_number,
au.type_desc,
au.total_pages,
au.used_pages,
au.data_pages,
p.rows,
ips.index_depth
FROM sys.allocation_units au
JOIN sys.partitions p
ON au.container_id = p.partition_id
JOIN sys.indexes i
ON p.object_id = i.object_id
AND p.index_id = i.index_id
JOIN sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.tst'), NULL,
NULL, NULL) ips
ON p.object_id = ips.object_id
AND p.index_id = ips.index_id
AND p.partition_number = ips.partition_number;
[/sql]
The result should look like this:
The Scan
Now let's run a very simple query against that table:
[/sql]
This query is going to use a Scan Operator:
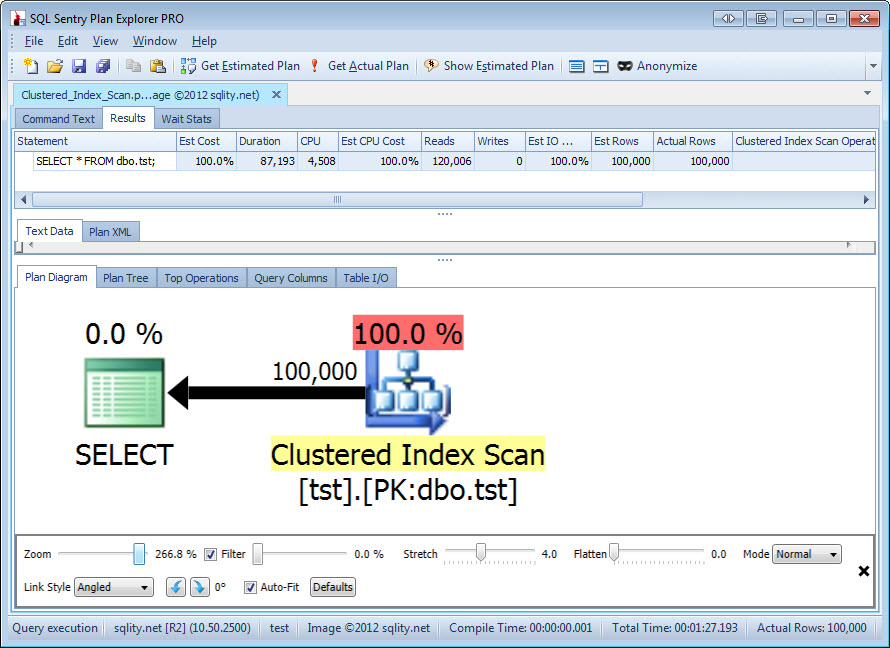
It makes sense for this query to use a clustered index scan, as we are asking it to return the entire table with all rows and all columns. If you look at the above screenshot you can tell that this query ran for about 87 seconds and read 120,006 pages. That is all 100,000 data pages and 20,006 of the about 25,000 supporting index pages. That is a little bit surprising as SQL Server knows what the first data page is. Also, all data pages are connected with each other in a double-linked-list. So you would expect SQL Server to only read the 100,000 data pages during a clustered index scan. The reason for that over-read is however beyond the scope of this post. Important is that a scan reads almost all of the pages in an index.
The Seek
To get a seek query we are just going to add a simple WHERE clause to the query:
[/sql]
As expected, this query is using a Seek Operator:
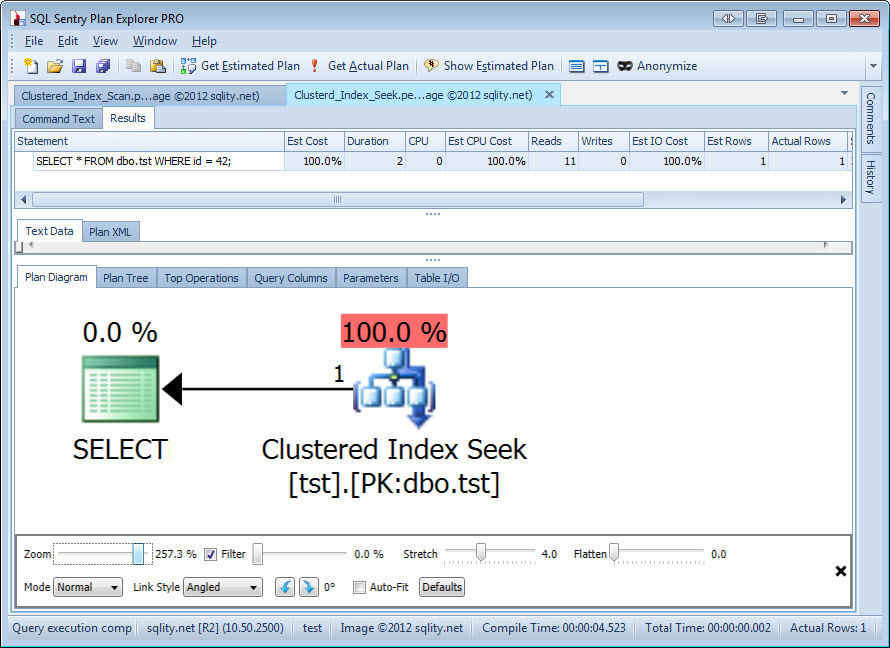
This query finishes in about 2 milliseconds and executes 11 reads. That is one read for each of the 8 index levels and then 3 more, because SQL Server likes to do additional work when dealing with clustered indexes as we have seen before. As you can tell, an index seek is significantly faster because it has to do a lot less work to get to the data.
Now, the above two queries cannot really be compared with each other as the one is returning the entire table whereas the other one returns only a single row. But if you were executing a query that is also returning a single row but can't make use of the index, SQL Server would have to execute the same expensive full clustered index scan to find that row.
The Scanning Seek
Now so far everything was pretty straight forward and probably no surprise to you. Now let's look at this query:
[/sql]
This query is going to, like the first query we looked at, return all 100,000 rows in the table as the id column is defined as an IDENTITY(1,1) column, so all id values are going to be larger than 0. Therefore we would expect to see a Clustered Index Scan Operator in the execution plan.
However, when you look at the execution plan, there is a Custered Index Seek Operator grinning back at you:
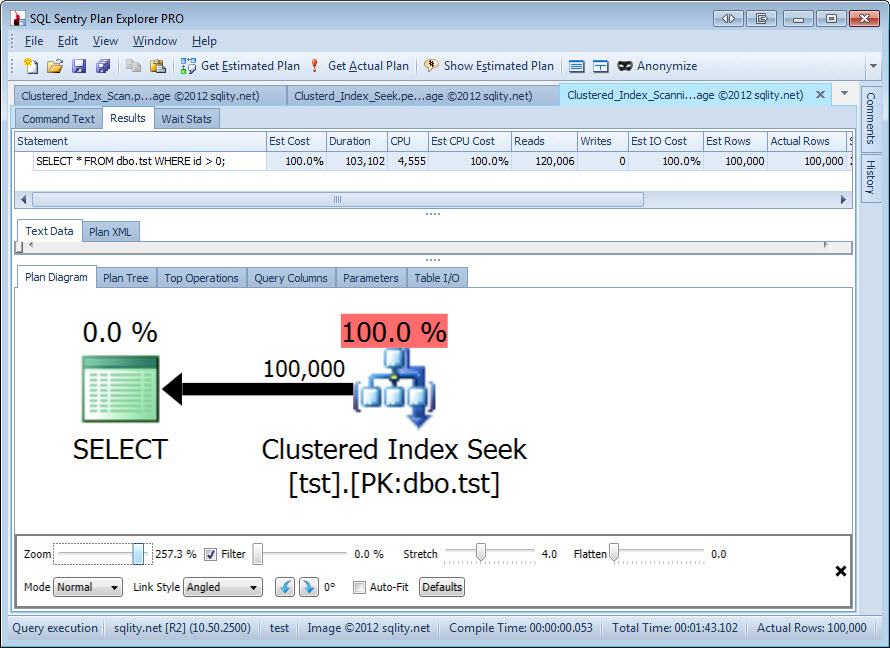
If you look at the execution time and the number of reads SQL Server executed you will find that it took about as long as the clustered index scan we looked at before. SQL Server also used the exact same number of logical reads: 120,006. So, everything is screaming that this in fact was a full clustered index scan operation. Just the plan seems to tell us otherwise.
Deception
The reason for the behavior you saw above is that the operator is only telling us how SQL Server is going to find the first row of the result. After that first row is located, SQL Server might scan in either direction of the index to retrieve further rows. This scan can happen, as we have seen, under either data access operator.
So the take away for you is, that a Seek Operator in an execution plan does not necessary mean that everything is in great shape. You need to look deeper to see what SQL Server is actually doing with that operator.
There are a few more examples where the Seek Operator is doing more work that the execution plan is telling you on first glance and I might write a follow-up article later to show more of them. Until then, be alert and don't trust that Deceiving Seek Operator.
Newsletter Sign Up
2 Responses to The Deceiving Seek Operator [TSQL Tuesday #043 – Hello, Operator?]
Leave a Reply
You must be logged in to post a comment.

We know how to make a database not slow. We’ll help you do the same.

From the sqlity.net blog
-
How to identify the SQL Server Service Account in T-SQL

-
How to Change a SQL Login’s Password

-
Hash Algorithms – How does SQL Server store Passwords?

-
How to Re-Create a Login with only a Hashed Password

-
B+Trees – How SQL Server Indexes are Stored on Disk

-
The Hidden SQL Server Gem: UPDATE from SELECT

-
A Join A Day – Nested Joins

-
Determine the Uptime of a SQL Server Instance

-
A Join A Day – The Left Anti Semi Join
-
Log Reuse Waits Explained: LOG_BACKUP

Pingback: Rob Farley : Plan Operator Tuesday round-up
Pingback: Plan Operator Tuesday round-up – LobsterPot Blogs